模型不是工具:為什麼 Spark 不能靠自己產圖




最近想榨乾訂閱帳號的價值,我打了一個如意算盤:用額度獨立的 Spark(gpt-5.3-codex-spark)去呼叫 GPT Image 2 幫我產圖。Spark 的額度跟 Codex 主帳號分開算,理論上很划算。
結果怎麼弄都不會動。
去翻 Spark announcement 才看到 OpenAI 自己寫得很白:
https://openai.com/index/introducing-gpt-5-3-codex-spark/
Spark 目前是 text-only。
我一開始把這句話讀成「模型沒辦法產圖」就放棄了。但停下來想想,其實是我把兩件事混在一起:模型能不能輸出圖片,跟模型能不能呼叫產圖工具,根本是兩回事。
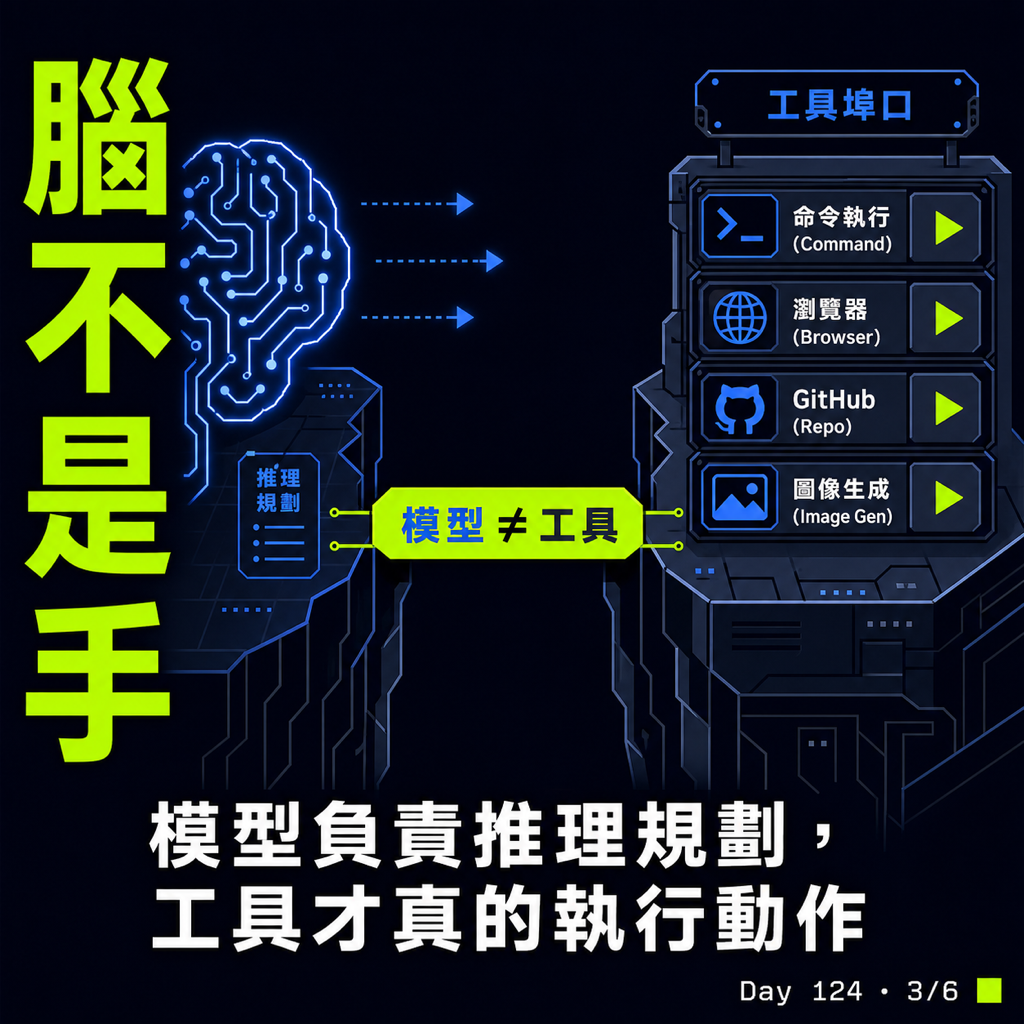
模型像大腦,負責推理跟決定下一步。工具是 runtime 在這次 session 真的有發給它的能力——對電腦下指令、讀寫檔案、控制瀏覽器、產圖,都是工具。runtime 才是發工具的人。
Spark 是 text-only 的意思,是它自己沒辦法直接吐圖片 bytes。但只要 runtime 願意把 image_gen 注入進來,Spark 就能去呼叫——真正產圖的還是後面的 GPT Image 2,image_gen 只是這個 session 的入口。
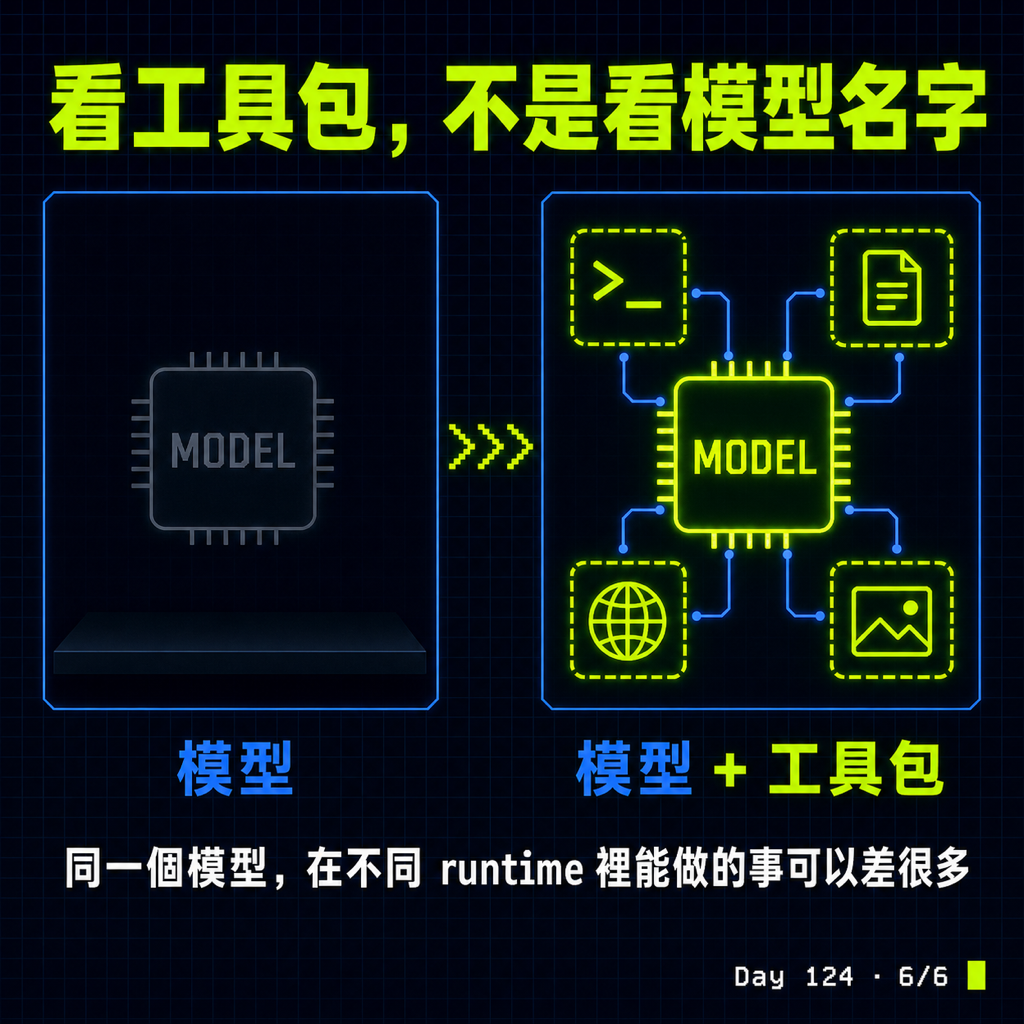
注意到了嗎?這跟「模型夠不夠聰明」無關,關鍵是這個 session 的 runtime 有沒有把 image_gen 接上。
沒接上,prompt 裡寫一百次「你有 image_gen 工具」也沒用,模型沒地方送 tool call。就像你嘴上說我有相機,現場沒發相機,照片還是拍不出來。
所以 Spark 想自己產圖這條路是死的。如果硬要讓 Spark 帳號產圖,能走的就是另外開腳本,用 OpenAI API 直接打圖片模型——但那就吃 API key 的錢,不是 Codex 訂閱的額度,回到原點。
Claude Code 也是同一套架構:Claude 是模型,Claude Code 這個 runtime 發 Bash、Read、Edit、WebFetch 那些工具,要再多接外部能力就走 MCP。重點是工具不是 prompt 寫一寫就會生出來的,是 runtime 真的註冊進去才算數。
這次學到的事其實只有一句:選 agent 的時候不要只看模型名字,要看這個 session 配到的工具包。同一個模型在不同 runtime 裡,能做的事可以差很多。
reasoning effort 調再高也只是讓它想更久,不會憑空多一個 image_gen。