逐字稿不要直接拿來用





最近去一場實體聚會交流,聊到逐字稿辨識度的問題——大家不約而同都在用 Whisper(OpenAI 開源的本地語音轉文字,Day 82 介紹過:https://dawsonwang.com/day/82)跑錄音,但直接把逐字稿拿來用幾乎都踩到同一個坑:辨識錯字、人名亂跳、口頭重複全部如實照打,要從裡面挖出能用的東西很累。
這篇分享兩件聊完之後我才把想法整理清楚的事:第一個是逐字稿要再過一層才好餵 AI,第二個是有些場景連「自己按錄音」這條路都該換做法。
Whisper 出來的是半成品
Whisper 跑出來的是「聽起來最像什麼」的純語音辨識結果——它沒有「這個語境下該是哪個字」的判斷能力。
常見的狀況:
- 專有名詞亂跳:同一個人名前後可能被寫成三個版本
- 同音異字:「prompt engineering」變「promote engineering」
- 講者改口、結巴、贅字全部如實照打
如果你直接把這份逐字稿貼給 AI 當素材(像 Day 82 那種「把音檔變成顧問素材」的用法),AI 拿到的其實是一份內含雜訊的低品質資料——後面再怎麼問都會被污染。
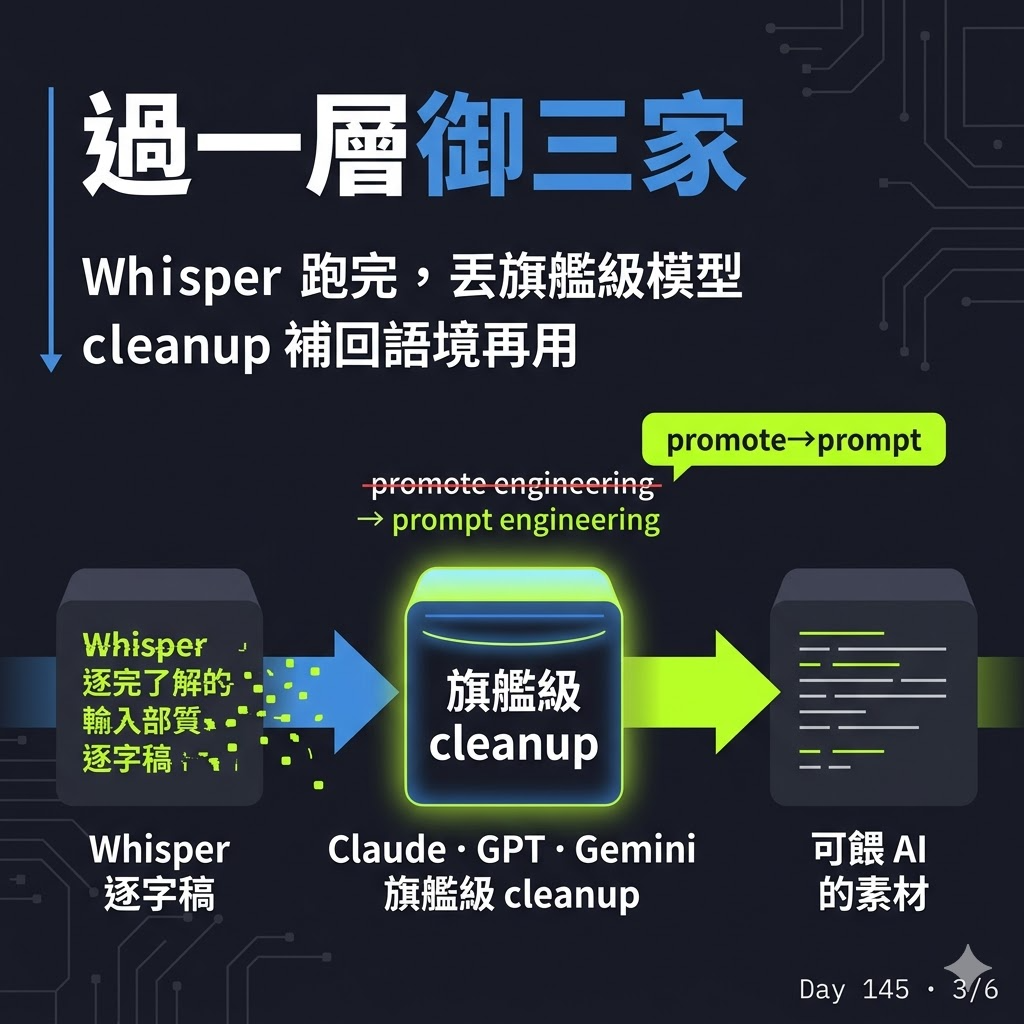
過一層御三家的高階款
我的標準做法是:Whisper 跑完之後,再丟給御三家(AI 圈習慣的說法,指 Anthropic、OpenAI、Google 三家)的高階款做一遍 cleanup——Claude Opus、GPT-5.5、Gemini 3 Pro 這類旗艦級模型都行。Prompt 大致長這樣:
這是 Whisper 跑出來的逐字稿,主題是 X。
請幫我修正辨識錯字、補回語境合理的專有名詞、
拿掉口頭重複跟結巴,
但保留每個人實際說的內容,不要重寫、不要摘要。
高階模型的差別在於——它真的在理解這段話講什麼。看到「promote engineering」配上前後文是工程師對談,它會自己判斷該是「prompt engineering」改回去。便宜的小模型做不到這件事,它會把錯字當對的照吞,有時候還會自己加戲、亂改原意。
cleanup 過的逐字稿才是「能拿來餵 AI 當素材」的版本。多這一步,後面所有問答的品質都會跟著拉起來。
純錄音的天花板:分不出誰在講話
第二個更根本的問題:純錄音本來就只能得到一整塊沒有講者標記的純文字。
兩個人對談還好,上下文還能猜出誰是誰。但只要超過三個人,逐字稿讀起來就是:
對啊我覺得這個 case 很有意思
對對對 但我們之前的經驗是
其實我比較傾向另一個做法
——誰是誰完全分不出來。後面要做「整理 A 講者的觀點」「找 B 提到的待辦」這種事就直接卡死,連御三家也救不回來——因為講者資訊根本沒進來過,cleanup 也補不出來。
線上會議走 Vexa 那條路
這時候 Day 141 介紹的 Vexa(https://dawsonwang.com/day/141)就是另一條路。它不是「我自己按錄音」這條——而是派一隻 bot 進會議,bot 拿得到平台給的與會者清單(誰是 host、誰在第幾分鐘加入),轉錄結果直接帶講者標記:
[Dawson] 對啊我覺得這個 case 很有意思
[Alice] 對對對 但我們之前的經驗是
[Bob] 其實我比較傾向另一個做法
辨識當然不會 100% 準——同時講話、講者切換很快、或音質不好的段落還是會出錯。但有講者標記跟沒有之間的差距,遠大於「偶爾標錯」帶來的損失。錯了你可以快速校正;沒有,你連校正的對象都沒有。
實體聚會這條目前還沒有對應方案——沒辦法派 bot 進實體會議室,只能靠純錄音 + cleanup 撐著。但線上會議就完全不一樣了:Vexa 那套設定好之後,後面 AI 處理都有「講者維度」可以用。
一張表整理
| 場景 | 推薦做法 |
|---|---|
| 個人語音筆記 / Podcast | Whisper → 御三家 cleanup |
| 線上會議(Meet / Zoom / Teams) | Vexa bot 入會 + 講者標記 → 御三家 cleanup |
| 實體聚會 | 純錄音 + Whisper + 御三家 cleanup |
| 想餵給 AI 當長期顧問素材 | 一定要過 cleanup 那一層 |
逐字稿不是 Whisper 的終點,是中繼站。少了 cleanup 這一層、或少了講者維度,AI 拿到的就只是半成品——後面再怎麼問都救不回來。
Sources:
- Whisper: https://github.com/openai/whisper
- Vexa: https://github.com/Vexa-ai/vexa
- Day 82 Whisper 把音檔變成顧問素材:https://dawsonwang.com/day/82
- Day 141 線上會議記錄開源神器 Vexa 實測:https://dawsonwang.com/day/141