AI 的怪詞為什麼列不完






你大概也遇過:AI 幫你寫的中文,讀起來總有幾個詞卡卡的、但一時講不出哪裡怪。
我自己最近就被抓到一個。Day 156 那篇的草稿裡,我形容一個被擋掉的請求是「訊息只有乾乾的一個 Error」。有人提醒我——沒人會用「乾乾的」去形容一個 Error。我回頭看,確實,母語者不會這樣講,發布前就把它拿掉了。但問題不在這一個詞,在它後面那一整類。
這篇想搞懂一件事:AI 寫的中文,為什麼老是冒出幾個「聽起來合理、但沒人這樣用」的詞?還有更現實的——這種詞到底擋不擋得掉。
我第一個念頭很直覺:建一份禁用詞清單,做成 lint(自動掃出怪詞的那種檢查),看到一個擋一個。
這條路當場就破功了。我把問題丟給 AI、請它想辦法,它在同一段對話裡又生出一個新的——它寫「最後一句誠實話」。但「誠實話」根本不是固定講法,道地的是「老實說」「講真的」「說實在的」。清單還沒建起來,就先多一個沒收錄的新詞。
AI 是用「組」的,母語者是用「取」的
差別在這裡:
母語者講「老實說」,是從腦裡「取」一個大家早就講定的固定講法,整塊拿出來用。
AI 寫「誠實話」,是現場把「誠實」加「話」「組」出一個聽起來合理、但實際不存在的搭配。「乾乾的一個 Error」也一樣,是現場拼出來的修飾,不是取一個現成的說法。
關鍵就在這句:怪詞是「生成」出來的,不是「有限」的。你封掉一個,它現場再拼一個新的。要去列舉一個無限的集合,當然列不完——清單沒有盡頭,不是因為你不夠勤勞,是這件事本身就列不完。
不是「先用英文想再翻成中文」
很多人以為 AI 中文怪,是因為它先用英文想、再翻回中文,翻得不到位。
比較準的講法是:它是直接生成中文的,中間沒有一道翻譯。只是它學中文的時候,讀到的料以英文跟簡體居多,下筆的直覺整個被那批料拉歪了。看起來像翻譯腔,但其實沒有在翻譯——是它的語感本來就被養偏。
「按需」「視頻」這種詞會自己跑出來,也是同一個原因。
那給它一個「人格」呢
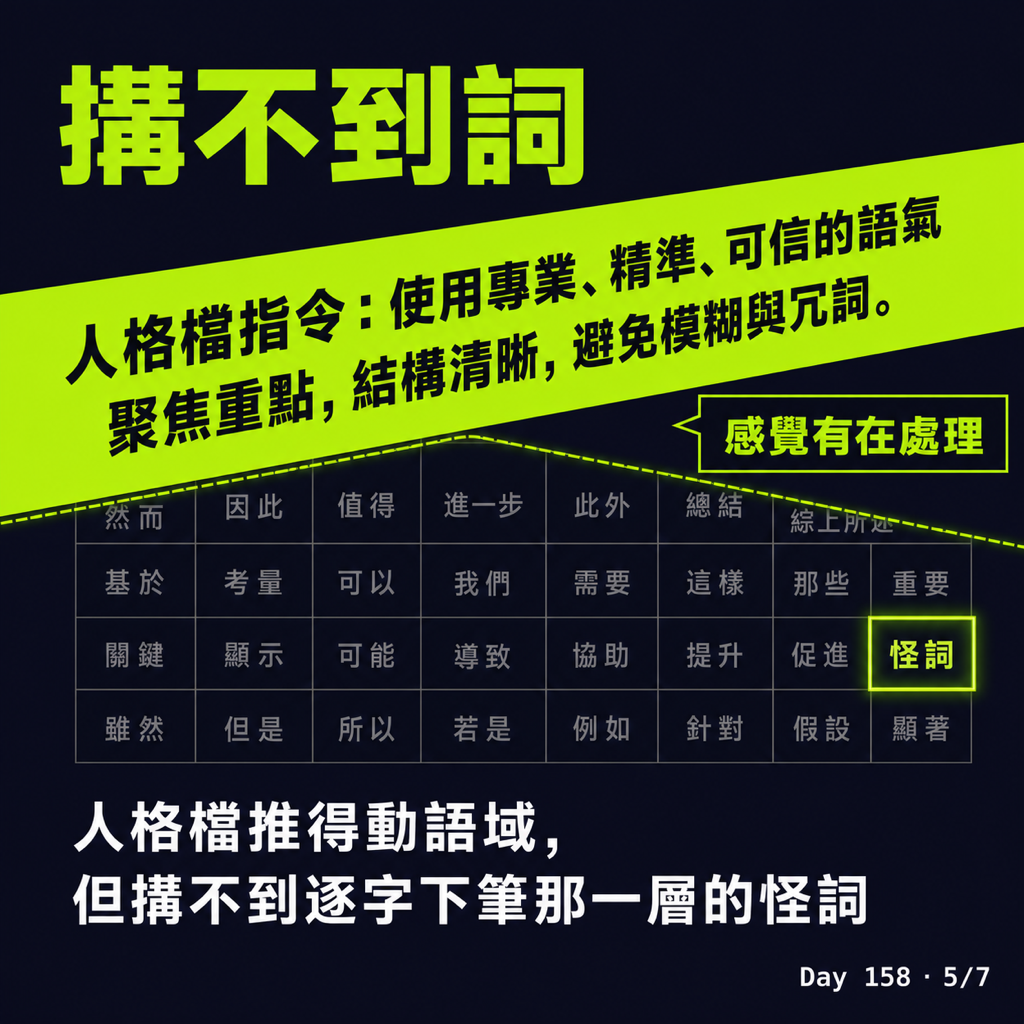
有人會想到另一招:像 OpenClaw 那種做法,給 agent 一個人格檔(soul / personality,一段宣告「你是誰、你怎麼說話」的設定),開頭就寫死「你是台灣文字工作者,全程用道地口語潤飾」,從源頭把語感調對。
我想過,但它跟禁用詞清單一樣,骨子裡都是同一招——寫一段描述給模型看,期待它照辦。它推得動「語域」(整段話整體偏正式還偏口語),讓全文往對的方向偏一點,這個有效。
但它推不到「詞」那一層。要不要寫「乾乾的」,是模型在逐字下筆的當下、很局部的決定;一句開頭的人格宣告,搆不到那麼細。更麻煩的是——「誠實話」對它來說根本不是錯,它就覺得很道地。你叫一個有盲點的人「請更道地一點」,他不會修掉自己看不見的東西。人格檔給你的是「感覺有在處理」,不是「真的攔得到」。
那要怎麼辦
人格檔當底盤可以,但別當解法。真正有用的還是兩個方向:
一,用 few-shot(直接丟幾段自己真的寫過的文字給它照著模仿)。與其列舉怪詞,不如把它要學的範本,換成一批本來就不含這些怪詞的東西。這不需要窮舉,而且你封不封清單它都成立。
二,檢查要查「機制」,不要查「清單」。與其問「有沒有命中禁用詞」,不如問:「這個搭配,是真實存在的固定講法,還是聽起來合理的臨時拼裝?把臨時拼裝挑出來。」這種問法抓得到「誠實話」這種沒見過的新詞;清單只認得它收過的那幾個。
但清不乾淨,先講清楚
就算這兩招都上,也清不乾淨:
同一個模型自己查自己,常常放行——因為它跟下筆的時候是同一個盲點,它就覺得「誠實話」沒問題。
換一個模型來查(像我本來就讓 Codex 順手 review),會多抓到一些,因為兩邊盲點不完全一樣;但大家共用「英文重、簡體重」這些大毛病,所以也不是解藥。
真正靠得住的那一關,還是人。剛剛抓到「乾乾的」的,不是任何工具,是讀的人。
所以務實的擺法不是「自動清乾淨」,是「盡量少來煩你」:few-shot 把頻率壓低 → 換個模型掃掉一批 → 人來守最後一關,這關外包不掉,要的是母語感。
那份禁用詞清單還有用嗎?有,但它的角色不是「擋掉所有錯」,而是一個 cache——把「乾乾的」「按需」這種重複犯的先擋下來,讓人省下力氣,去顧那個剛冒出來、還沒人見過的新詞。
AI 的怪詞列不完——但你真正要顧的,從來只有它新生出來的那一個。