省 token 的 Headroom 實測





最近用 Claude Code 有種感覺:同樣的 $200 額度,好像比之前更快見底。沒去細查是不是真的縮水,但這幾天確實開始想——有沒有什麼工具能幫我把 token 用量壓下來一點。
於是抓了 Headroom 來掛著跑。它的定位很直接:在你的 AI agent 把東西送進模型之前,先壓縮一輪——工具輸出、log、搜尋結果、檔案、對話歷史,全都先瘦身。README 主打 60–95% fewer tokens、local-first、可回取原文。
掛了三天之後,我把儀表板的數字撈出來。結論先講:有省到,但沒有 README 講的那麼神,而且更要命的是——我體感它明顯變笨了。所以我不推。
怎麼接的
我沒有一個一個模式去試。它有 library、proxy、MCP、wrap agent 四種接法,對天天泡在 Claude Code 的人來說最沒摩擦的就一條:
headroom wrap claude
一行命令,它幫你把 Claude Code 的流量導去本機的 proxy 壓縮,中間什麼設定都不用改。然後就是正常工作,它在背後默默做事,儀表板開 localhost 看數字。
儀表板上的真實數字
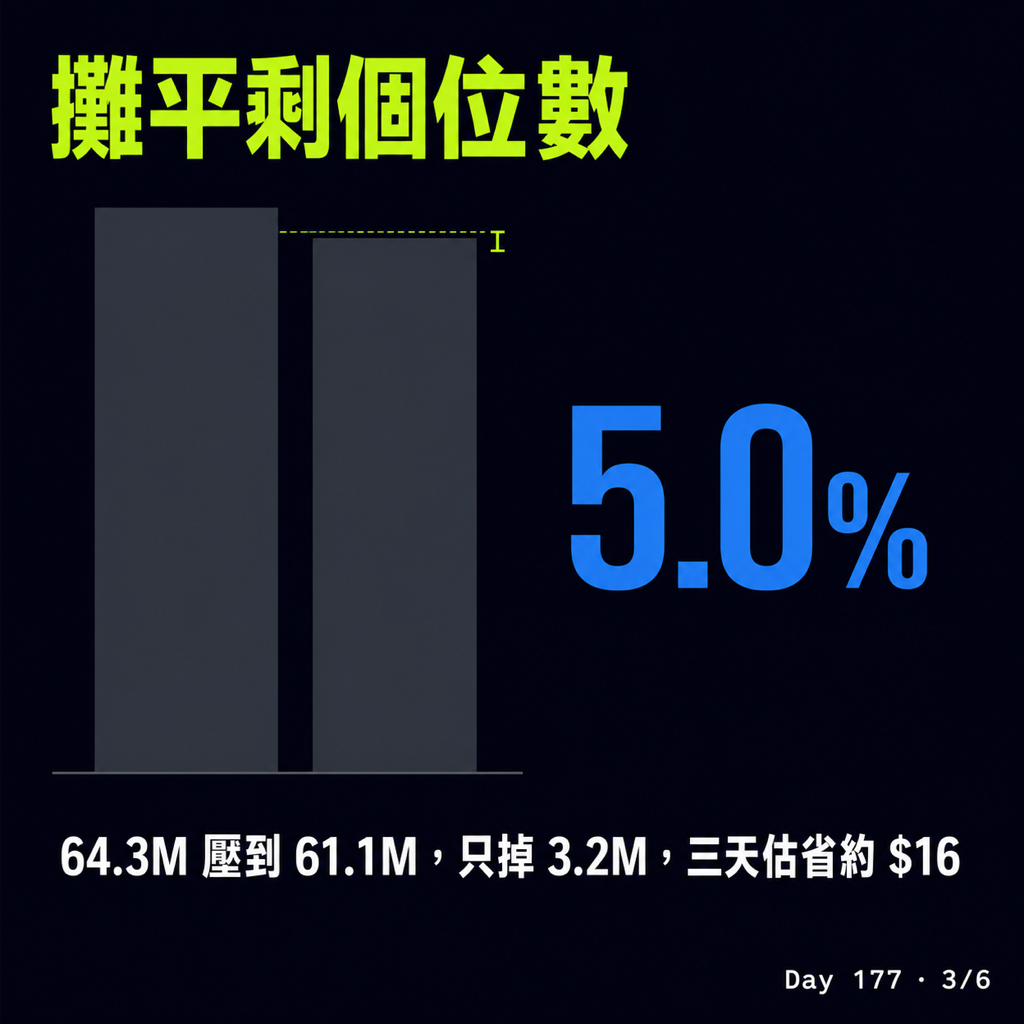
我直接報儀表板(版本 0.27.0,主力跑 Opus 4.8)那幾張卡片的數:
- 經過它的 token:Before 64.3M → After 61.1M
- 壓掉 3.2M token,整體 5.0%
- 最猛的一次:30,545 → 12,497 token,壓掉 59%
- 換算帳單估省約 $16(5.9%)(這是 Headroom 用 API 牌價估的,跟 $200 訂閱上限是兩套不同的基準,別硬湊)
這裡的 5.9% 比上面 token 的 5.0% 高一點,是因為被壓掉的多半是比較貴的 output token,所以省下來的錢佔比會稍微高一些。
不是零,但離 README 那個 60–95% 的招牌數字差很遠——攤平到日常流量,就是個位數。
為什麼平均只有 5%
關鍵在「不是每個請求都壓得動」。看儀表板的明細,真正有被壓到的大概只有一半,另一半都壓不動:有的根本沒有可壓的內容、有的 prefix 被快取凍結(不能動,動了快取就失效)、有的太小不值得壓、有的直接放行。光是「沒有可壓內容」這一類就佔了最大宗。
所以那個 60–95% 是會出現,但只出現在「一次塞一大坨結構化輸出」的請求上——像那次 59% 的,多半就是一大包搜尋結果或 log。可是日常 coding 的流量大多不長那樣,平均拉下來就剩個位數。
換句話說,README 的數字沒造假,但那是精選場景的上限,不是你掛上去就會拿到的日常值。
我覺得它明顯變笨了
這段要先講清楚:是體感,不是實測。Headroom 的儀表板只量 token 跟錢,不量回答品質,所以下面是我的印象、不是數據。
但這個印象很明顯。掛著它跑的這幾天,Claude Code 的回答品質掉得很有感——同樣的任務,它更常抓錯上下文、答得更鈍,有幾次我得多來回幾輪才把它導回正軌。這很合理:壓縮本質上就是丟掉一些東西,丟對了沒事,丟到關鍵那段,模型就是會變笨。它有 CCR 可回取機制(原文留本機,模型需要時自己撈回來),理論上能補,但模型不一定每次都知道要去撈,實際上就是補不回來。
我沒有跑對照組去量這件事,所以這頂多是強烈的印象、不是證據。但它強到足以讓我把工具拔掉。
那這東西到底推不推
不推。
省 5%、三天大概 $16,換來的是回答明顯變笨——這筆帳怎麼算都不划算。token 是省了,但我得多花來回把模型導回正軌,省下的時間又賠回去,甚至倒貼。
硬要說它的適用場景:如果你的用量天天頂到額度上限、寧可答得鈍一點也要先能跑完,那它確實能擠出一些空間。但對絕大多數人——包括我——為了省一點錢賠掉品質,不值得。它自己 README 也寫了,只用單一供應商、吃原生壓縮就夠的,根本不用多接這層。
對我來說最大的收穫不是那 $16,是把「省 token」這件事的代價量清楚了:在真實的 Claude Code 工作流上,這類壓縮層省下的是個位數的量級,而換掉的品質卻很有感。便宜一點點、笨一截,這個交換我不要。
最近開始做免費的一對一諮詢,幫你把 AI 接進自己的工作流——有需要的話可以約:https://www.dawsonwang.com/
相關: Headroom:https://github.com/chopratejas/headroom 文件:https://headroom-docs.vercel.app/docs