我的第二大腦長這樣——Obsidian 加 Claude,三層機制全公開
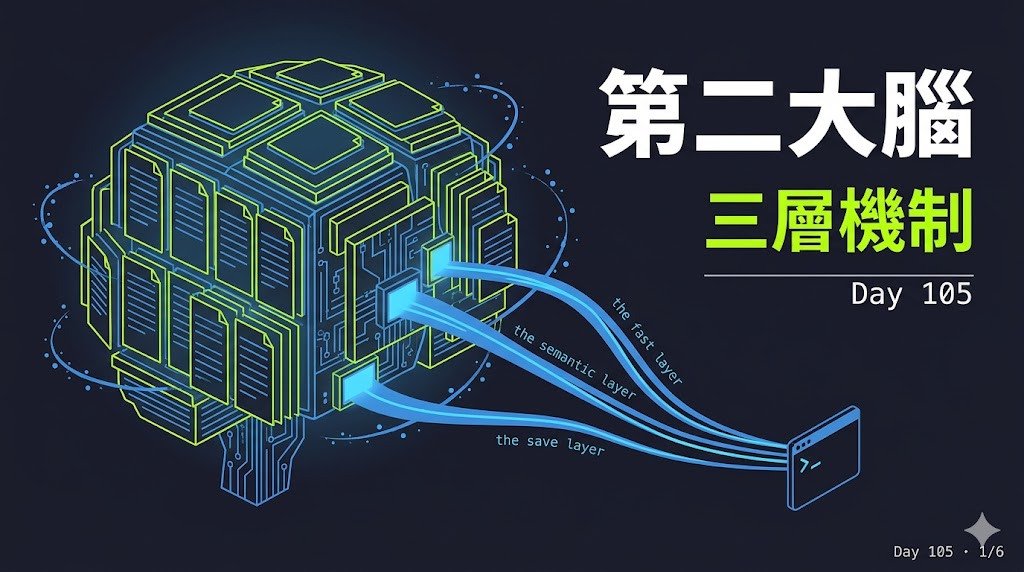




延續昨天的內容,Karpathy 提到他用 wiki 配 Obsidian 做第二大腦,我蠻有感的,因為這陣子也在折騰同一件事。只是我的版本激進一點——我不只是把筆記存在 Obsidian 裡,還要求 Claude 每次跟我對話之前,都先讀過我的筆記再回我。
所以今天想分享的不是「要不要做第二大腦」,而是一旦你決定要做,怎麼讓它真的跟你一起工作,而不是另一個「建好就沒再打開」的資料夾。
先講結論:我有三層機制同時在跑。讀的時候便宜的先跑、貴的用到才呼叫;寫的時候要有守門人,不能讓 AI 亂寫我的第二大腦。
【為什麼需要這個機制?】
平常我們會請 LLM 上網搜集資料,取得更多即時的內容後再回答我們,但更多時候需要的是個人相關的資訊,例如專案用什麼架構是因為什麼取捨、之前做的小工具它不知道可以拿來用、上次解掉的 bug 在另一個專案又出現了……這些資訊靠 Obsidian 補充超級有用,簡而言之都是從過去個人經驗學習。
但我們不可能把所有內容都一直往 CLAUDE.md 裡塞,雖然過一陣子會把部分內容當成 skill 分離出來,但終究還是有其極限。
如果我們可以設計一個動態的 CLAUDE.md,是不是這種問題就能解決?
這也呼應到之前提到的 Harness Engineering——如果我們希望每經一事就漲一智,那一個經驗值的累積系統就顯得十分重要。
如果我們不能直接把知識寫死,那麼每次只把相關的知識注入如何?但這樣跟查詢又有什麼不同?
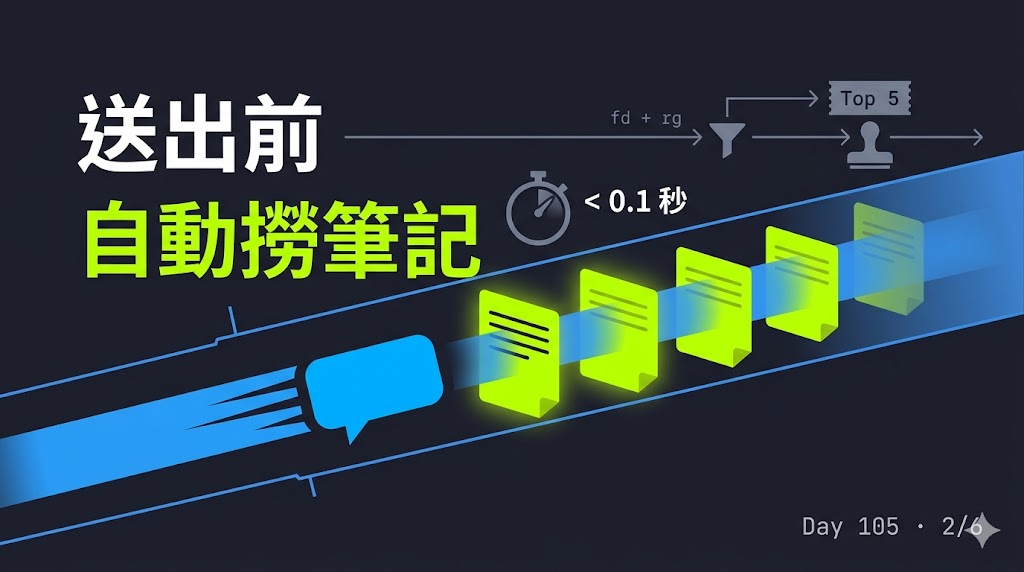
【第一層:每次送訊息前,先自動撈一輪筆記】
這層最有感。Claude Code 有個機制叫 UserPromptSubmit hook——白話就是"我按送出之前"的攔截點。它會先跑一段 bash 小腳本,把結果當背景資料塞給 Claude,Claude 才開始回我。
我掛在上面的是一個叫 obsidian-search.sh 的腳本,做的事很簡單:
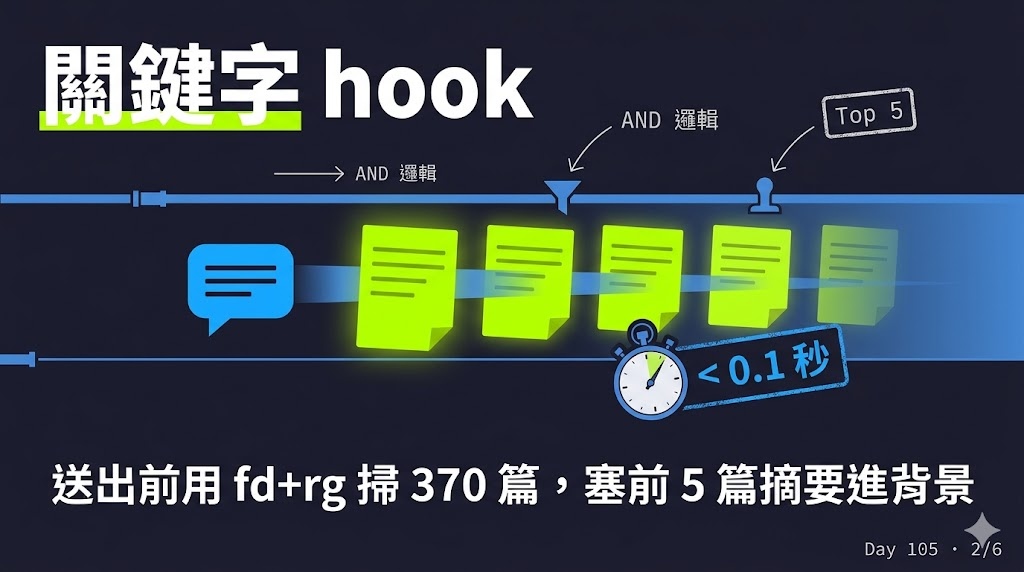
→ 從訊息裡切出關鍵字(過濾掉 the、about、note、claude 這種意義很薄的詞) → 用 fd 跟 rg 這兩個快到不像話的搜尋工具,一個掃檔名、一個掃內文 → 挑出前 5 篇最相關的筆記 → 把筆記開頭幾行的摘要塞進背景資料
這裡刻意用"關鍵字搜尋"而不是"語意搜尋"(前者是字面比對,後者是讓 AI 理解你真正的意思)。為什麼選便宜的?因為快。fd 跟 rg 本地掃 370 篇筆記不到 0.1 秒,完全感覺不到卡頓。
我還加了一堆守門條件:訊息太短不跑、斜線指令不跑、"fix this"、"commit"、"git" 這類純粹叫 AI 幹活的指令不跑——這些情境根本不需要第二大腦。
最關鍵的一個設計是"AND 邏輯":同一篇筆記裡要同時出現兩個以上關鍵字才算命中。只有一個關鍵字就做全文比對,結果會太雜。這個細節讓命中品質提升非常多。
這層的定位就是:主動推、無意識觸發、便宜到不用想。
【第二層:需要語意搜尋時,才呼叫 MCP】
關鍵字比對的漏洞很明顯:兩篇筆記講同一件事但用不同的詞,就抓不到。這時候就輪到 obsidian-notes-rag MCP 上場(MCP 可以想成一套讓 Claude 主動呼叫外部工具的協定)。
它跑在我本機上,用 uvx(uv 提供的 Python 工具執行器)就能拉起來,而且不會太佔 context window,一共五個工具:
→ search_notes:丟一段描述,回傳意思上最接近的筆記 → get_similar:丟一篇筆記,回傳跟它最像的其他筆記 → get_note_context:拉某篇筆記附近的相關內容 → get_stats:看 vault 目前的索引狀態 → reindex:把整個筆記庫的語意索引重跑一次
370 篇筆記我都跑過語意索引(也就是 embedding),測試查詢的相似度大概落在 0.63 到 0.67,算堪用。
為什麼選這個而不是 Obsidian 官方那個?因為官方那個有個致命限制:它靠 Local REST API 外掛跟 Obsidian 溝通,也就是 Obsidian 這個 app 必須開著、外掛要啟用中,才能運作。
這對我來說無法接受。我常常關掉 Obsidian 專心寫程式,甚至 Obsidian 都還沒開、電腦就已經在跑 Claude Code 了。一個"你必須開著某個 GUI 才能讀筆記"的設計,本質上不是可靠的自動化基礎。
obsidian-notes-rag 不一樣——它直接讀 vault 資料夾裡的 markdown,加上自己維護的一份語意索引,跟 Obsidian app 開不開完全無關。我關掉 Obsidian、甚至重開機,只要 uvx 能啟動它,它就能搜。
重點是:這層是"被動呼叫"(pull-based)。Claude 自己判斷"光靠關鍵字不夠"才會呼叫。我不強迫它每次都跑,因為語意搜尋比關鍵字搜尋貴得多。
這裡的"貴"不是錢——MCP 跑在本機,一毛不用付。我講的是三種成本:
→ 延遲:關鍵字搜尋不到 0.1 秒;語意搜尋要先把問題轉成向量再做相似度比對,通常要一兩秒。每次送訊息都等一下,累積起來很煩。 → 對話記憶空間(context window):關鍵字 hook 每次只塞幾百 token 的摘要;如果改成每次都做語意搜尋,對話視窗很快就被筆記塞爆,真正對話的空間反而被壓縮。 → 判斷力:被動呼叫代表 Claude 每次都要先決定"要不要查、用什麼關鍵字",這個決策本身在吃思考資源,而且常常判斷錯、亂查一通。主動推的關鍵字 hook 零決策成本。
所以"貴"的真正意思是延遲、對話空間被塞爆、決策負擔。錢反而是最不重要的那個維度。
便宜的自動跑、貴的用到才呼叫,這是整個設計的核心。
【第三層:對話結束後,提醒我把知識存進去】
讀的機制講完了,換寫的。
Claude Code 還有一個叫 Stop 的 hook,會在 Claude 回完話之後觸發。我掛了一個 secretary-stop.sh,它要判斷兩件事:"對話是不是真的結束了"以及"有沒有值得存下來的東西"。兩個都符合,就塞提示進去,讓 Claude 呼叫我的 obsidian-secretary skill,把重點整理成原子化的小筆記寫進 vault。
這裡最難的是判斷"對話到底結不結束"。我試了很多版本才調到現在這樣:
→ 回答太短不算(少於 300 字) → 還在跑背景任務(像 ralph-loop)或子代理人工作中的 session 不算 → 回答裡出現問號、"你要不要"、"要我做"這類句子不算(Claude 還在等我回話) → 有"下一步我會"、"接下來"這類繼續做事的訊號也不算 → 一定要出現"that's it"、"都弄好了"、"希望有幫到你"這種收尾語才算
第一版沒想這麼多,每一輪對話都觸發,Claude 被煩到崩潰。後來一條一條加守門條件,現在這版才比較像一個有分寸的秘書。
還有一條重要守門:對話內容已經出現"已經存到 obsidian"這類字樣,就不能再觸發,不然會變成無窮迴圈。
【最後一塊拼圖】
最後我缺少的是昨天 Karpathy 那個 wiki——不一定要照他的做法,但需要一個"做夢"機制,讓不同 note 之間的聯繫更緊密,類似腦神經重塑。
但我目前還在猶豫:如果全部交給 LLM,那品質控管要怎麼辦?這等於是完全信任 LLM,但我們都知道這很不可靠,所以是不是要先寫測試來調教品質後才放養?大家有什麼好想法嗎?