Token 不夠用的解法--Subagent






Token 大放送的日子已經過了。如果你常常覺得 Token 不夠用,那一定是你的 subagent 用的不夠多。今天來詳細說明一下 subagent 的使用策略。
最近觀察到一件有趣的事:大家都在談 skill——怎麼寫、怎麼組織、要用 skill-creator 做出哪些花樣。但 subagent 這個東西,討論度反而低得不成比例。我覺得這是滿大的盲點,因為兩者根本不是同一層級的工具。Skill 是把提示詞和知識打包成可呼叫的模組,本質上還是在你的主對話裡跑;subagent 是真正把一整塊工作"搬到另一個房間"去做完,只把結論拿回來的機制。前者省的是"每次要重新講一遍"的力氣,後者省的是"主對話 context 被灌爆"的結構性成本。
這兩個層級不處理,光在 skill 上精雕細琢,省下的空間遲早會被吃回去。
【先搞懂 subagent 到底在省什麼】
Subagent 是一個獨立的 Claude session,有自己的 context window、自己的系統提示詞、自己的工具權限。Claude 遇到適合的任務就把它派出去,subagent 自己做完之後,只把"結論摘要"回傳給主對話。
這個設計解決的不是成本問題——是 context 爆炸問題。
舉個很實際的例子:你叫 Claude 幫你找"這個 repo 裡所有用到某個函式的地方,然後告訴我哪些寫法有問題"。如果直接在主對話做,Claude 會 grep 一百個檔案、讀五六十個 component、把幾千行 code 灌進 context,等它要給你答案時,你的對話視窗已經被垃圾塞爆,後面幾輪就開始失憶、開始重複問你先前講過的事。
改用 Explore subagent(內建的,跑 Haiku 模型、只讀不寫)做同一件事,主對話只會看到一段"我找到 x 個問題,分別是……"的摘要。十倍以上的 context 差距,而且是可以疊加累積的——你整個 session 做越多探索性工作,差距就拉越大。
我用這篇文章本身做了一個實驗:同一份 source.md、同一套 content pipeline,一次全程走 subagent,一次全部在主對話跑。 Sonnet 4.6 context 佔用:
- 無 subagent:61%
- 有 subagent:22%
快三倍的差距,來自同一份輸入、同樣的工作量。
同時我們也知道佔用的 context 越少品質會更好,因為更沒有注意力稀釋問題,也代表可以處理更多任務。
實測結果也是沒有用到 subagent 的版本品質的確比較差。
【Subagent 的 context 起點:帶什麼、不帶什麼】
理解這份清單,你才知道 subagent 是在什麼樣的"空白狀態"下開始工作的。
帶進去的: → MCP servers:預設全帶。主對話有的 MCP 工具,subagent 都能用。也可以在 frontmatter 的 mcpServers 欄位限縮或額外新增。 → 工具權限:預設全繼承,可用 tools(白名單)或 disallowedTools(黑名單)欄位限制。 → Permission context:從主對話繼承,可用 permissionMode 欄位覆蓋。 → 當前工作目錄:subagent 從主對話的工作目錄開始執行。 → CLAUDE.md:全域的(~/.claude/CLAUDE.md)和專案的(./.claude/CLAUDE.md)都會載入,連同裡面 @-import 進來的 rule 檔案一起帶進去。但有一個很容易踩的細節:它是在主對話啟動時被快照進 context 的,session 跑到一半你去改 CLAUDE.md,新 spawn 的 subagent 看不到你的改動——要整個 Claude Code 重啟才會刷新。我用 canary 字串跑過兩輪實驗驗證過這件事:中途注入看不到,重啟後注入看得到,全域和專案兩邊都是這樣。
不帶進去的: → 主對話歷史:完全乾淨的 context,它看不到你和主對話講過什麼。 → Skills:主對話已載入的 skill 不會自動帶進去。你要什麼,就在 frontmatter 的 skills 欄位明列。
一個例外,也是個冷門但很好用的功能:用 claude --agent <subagent名稱> 啟動 Claude Code,整個 session 就會以那個 subagent 的 system prompt、工具限制、模型設定來跑。例如 claude --agent code-reviewer,開啟的 session 就是一個只讀不改、專注 review 的環境,啟動後 header 會顯示 @code-reviewer 確認身份。這是目前最乾淨的"把 Claude Code 變成專用工具"方法。
這份清單對寫 subagent 的人很重要——好消息是 CLAUDE.md 會繼承,全域和專案層級的規範 subagent 都收得到;但因為是啟動時快照,session 中間改了規則,記得重啟才會生效。
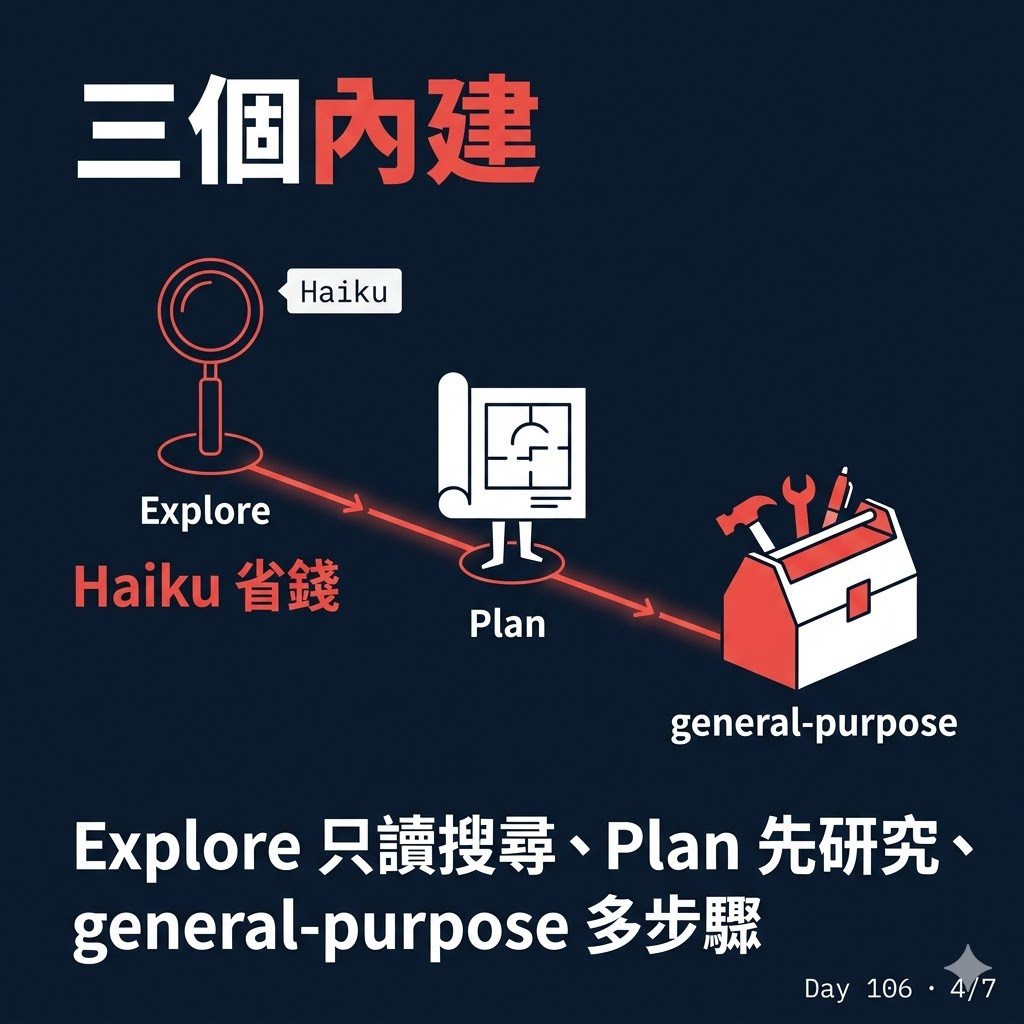
【內建 subagent】
→ Explore:跑 Haiku、只有唯讀工具,專門搜尋與分析 codebase。快、便宜、不會手抖改到檔案。 → Plan:plan mode 進去時會自動派它,也是只讀工具。它把研究做完才出計畫,避免 Claude 邊想邊亂改。 → general-purpose:所有工具都有,適合複雜、需要邊探索邊動手的多步驟任務。
光是記得這三個、在該用的時候主動說一句"用 subagent 做這件事"或"先用 Explore 去查",token 消耗量就會直接砍半。這是零成本、立刻見效的操作,沒有任何學習曲線。
當然,Claude Code 本來就會在某些時候自動派出這些 subagent——Explore 看到搜尋任務會自己去用,Plan 在 plan mode 下也是自動觸發。但如果你在自己的 skill 裡明確寫出"這一步用 subagent 跑",觸發就從概率行為變成確定行為,整體流程穩定很多。這也是為什麼寫 skill 的時候值得多花一行把 subagent 的使用方式寫清楚——Claude 自己會猜,但你明說它就不用猜了。
還有一件要記得的事:subagent 不能再派 subagent,這是架構層級的硬限制,沒有 flag 或設定可以繞。所以所有派遣都只能從主對話出發——不管你是一次派一個、並行派一排、還是序列化接力,dispatcher 永遠都是主對話本身。真的需要嵌套邏輯,就改用 skill 在主對話這層處理。這個限制反過來也是一種保護——不會讓你的 agent 失控遞迴下去。
【Skill 配 subagent:不是二選一,是疊加效果】
這一段是我覺得最多人搞錯的地方。
Subagent 的 frontmatter 裡有一個欄位叫 skills,可以在 subagent 啟動的當下,直接把指定的 skill 內容注入到它的 context 裡。而且要特別注意:subagent 預設不會繼承主對話的 skill——你要什麼得明講。
這代表什麼?你可以寫一個 api-developer subagent,在它的 frontmatter 裡指定 skills 是 api-conventions 和 error-handling-patterns,它一啟動就帶著你們團隊的 API 規範和錯誤處理模式去幹活。主對話根本不必載入這兩個 skill,那個 context 就省下來了。
反過來也可以——skill 本身可以加 context: fork 參數,讓整個 skill 在一個 fork 出去的 context 裡執行。fork 的是對話的 context window:沒 fork,skill 的搜尋結果、讀檔內容、工具輸出全部留在主對話;有 fork,這些通通關在 subagent 那邊,主對話只收結論。等於把原本"當場攤開做"的 skill 改成"搬到另一個房間做完再回來"。哪個當主、哪個當客,看情境選。
這組合的威力在於:skill 負責"要遵守什麼規範、要記得什麼知識",subagent 負責"在一個乾淨的空間裡按這個規範做事"。兩個合起來才是完整的工作流。
【MCP 配 subagent:把吃 context 的大胃王關進小房間】
這招我認為最被低估。
MCP 的 context 成本以前是個大問題:每接一個 server,所有工具的 schema 都會灌進主對話。Claude Code 啟用 tool search 之後改善很多——預設只載入工具"名稱",詳細描述要 Claude 用到才去搜尋拉進來。我本機上裝了 Playwright、Obsidian、Context7 一整排,現在啟動時也不會立刻吃掉幾千個 token。
但這個延遲載入有兩個漏洞:第一,工具名稱清單還是會列在主對話,接越多 server 清單越長;第二,如果你關掉 tool search、或用非 Anthropic 官方的 base URL,就會回到"全部灌進來"的舊行為。
更乾淨的解法:Subagent 的 frontmatter 有一個 mcpServers 欄位。那些重但只在特定情境才用的 MCP——例如 Playwright 只在要測 UI 時才需要——可以定義在 subagent 裡,而不是 .mcp.json 全域。
主對話完全不知道 Playwright 存在,連名字都不會出現在工具清單上,只有當 Claude 派 browser-tester subagent 出去時,那個 subagent 才會連上 Playwright 做事,做完回來時只丟摘要給你。
這招等於把你的架構從"預設常駐主對話"改成"用到才召喚 MCP",工具名稱不再外顯、特殊環境下也不怕回到老行為。瀏覽器類、資料庫類這種工具多又肥的 MCP,搬進 subagent 是一勞永逸的乾淨做法。
還沒完。搬進 subagent 同時也順手解掉另一個更常被忽略的問題:MCP 的回應成本。
就算你用 tool search 把 schema 擋在主對話外,實際呼叫時,MCP 的回傳值還是會整包塞回來。Playwright 的 browser_snapshot 一次吐幾千行 DOM、Obsidian 搜尋回傳十幾篇筆記全文、資料庫 MCP 拉一次 query 拖回一整批 row、Context7 抓一頁文件下來也是好幾 K token。Claude 最後真正要用到的往往只是"這顆按鈕在哪"或"這批資料裡誰過期了",但那份完整的原始回傳已經永久躺在你的主對話裡,吃掉後面每一輪的注意力。
搬進 subagent 之後,subagent 會在它自己的 context 裡吞下那份大回傳、做完分析,只把結論摘要丟回主對話。schema 不外顯 + 回傳不入侵,兩件事一次搬家一次處理完——這也是為什麼我說 MCP 配 subagent 的 CP 值特別高:它省下來的 context 是兩層疊加的,不是單點優化。
【Hook 配 subagent:生命週期自動化】
最後一塊是 hook。Subagent 有兩層 hook 可以掛,用途完全不同。
第一層:subagent frontmatter 裡的 hooks 欄位。可以設 PreToolUse(工具執行前)、PostToolUse(工具執行後)、Stop(subagent 結束時,會自動轉成 SubagentStop 事件)。這些 hook 只在該 subagent 活著的時候生效,結束就清掉。
實際用法:寫一個 db-reader subagent 只能跑 SELECT,你在它的 PreToolUse 掛一個腳本攔 Bash 命令,偵測到 INSERT、UPDATE、DELETE、DROP 就 exit 2 擋掉。Claude 自己想硬來都不行。這就是用 hook 幫 subagent 蓋一道結構性護欄。
第二層:專案的 settings.json 裡的 SubagentStart 和 SubagentStop。這兩個 hook 跑在主對話這一側,不是 subagent 裡面。可以讓你在某個 subagent 啟動時自動跑前置腳本(例如起 DB 連線、載入測試資料),結束時自動跑收尾腳本(關連線、寫 log、甚至通知你)。
兩層合起來,subagent 就不只是一個省 token 的工具——它變成一個有邊界、有守門、有生命週期管理的小工人。你可以像設計一個服務一樣設計它。
【結語】
省 token 的招數很多:壓縮 context、清歷史、換便宜模型、用 skill 把常用提示詞外掛化。這些都有用,但大多是治標。
Subagent 是治本:它從根本上改變"哪些資訊該進主對話、哪些不該進"的架構問題。
所以如果你還沒開始有意識地用 subagent,今天就去打開 /agents 指令看看、寫一兩個最常用的專屬 subagent。Skill 可以之後再補,MCP 可以慢慢搬,但 subagent 這件事真的不要再拖了——它是 token 不夠用時代最便宜也最有效的那個解。